
Le secret des Data Stores de Microsoft Fabric : Lequel est fait pour vous ?
Lakehouse, Warehouse, Eventhouse...

Bonjour à tous, je suis Antoine Wang.
J’aide les profils techniques à maîtriser l’architecture de Microsoft Fabric, et j’aide les décideurs à comprendre l’impact réel de cette technologie, sans le jargon inutile.
Mon objectif ? Vulgariser le complexe et vous donner les clés pour maîtriser Microsoft Fabric, une plateforme de données SaaS unifiée et alimentée par l’IA pour simplifier la gestion des données et l’analyse.
Cette newsletter est 100% gratuite. En vous abonnant maintenant, vous recevrez en exclusivité mon “One-Pager” pour cartographier l’ensemble de la solution Fabric en un coup d’œil.
Merci à celles et ceux qui me suivent depuis le début. Sans plus attendre, entrons dans le vif du sujet !
Aujourd’hui, on va regarder ensemble les outils pour stocker les données dans Microsoft Fabric.
Depuis le début de cette série, Microsoft Fabric n’est pas juste un outil de BI. C’est une plateforme unifiée qui gère tout le cycle de vie de la donnée. Avec les nouveautés comme l’arrivée de la SQL Database, du Mirroring des bases de données et de Snowflake Database, le menu s’est allongé.
Lakehouse ?
Warehouse ?
Eventhouse ?
Comment choisir le bon moteur de stockage sans créer une “dette technique” future ?
Voici votre guide de décision expert pour trancher en moins de 10 minutes.
Les Data Stores disponibles dans Microsoft Fabric
Microsoft Fabric ne propose pas un moteur unique, mais plusieurs magasins spécialisés. Tous ont un point commun fondamental : ils écrivent (directement ou indirectement) dans OneLake.
Cela permet de combiner les usages opérationnels et analytiques sans multiplier les copies de données. Le vrai enjeu n’est pas la puissance, mais l’usage.
Voici les 5 candidats :
1. Le Lakehouse : La flexibilité du “Tout-Terrain”
Le Lakehouse est l’artefact central pour les Data Engineers. Il combine le stockage flexible d’un Data Lake avec les fonctionnalités de gestion d’un Data Warehouse.
Ce qu’il faut retenir :
Prend en charge tout type de données : Structurés (Tables) et non-structurés (Fichiers).
Outil de développement : Apache Spark (Python, Scala, SQL, R).
SQL Analytics Endpoint : Un point de terminaison SQL (T-SQL) est créé automatiquement (en lecture seule) pour les analystes.
Idéal pour des tâches d’ingénierie de données, data science, architectures de médaillon.
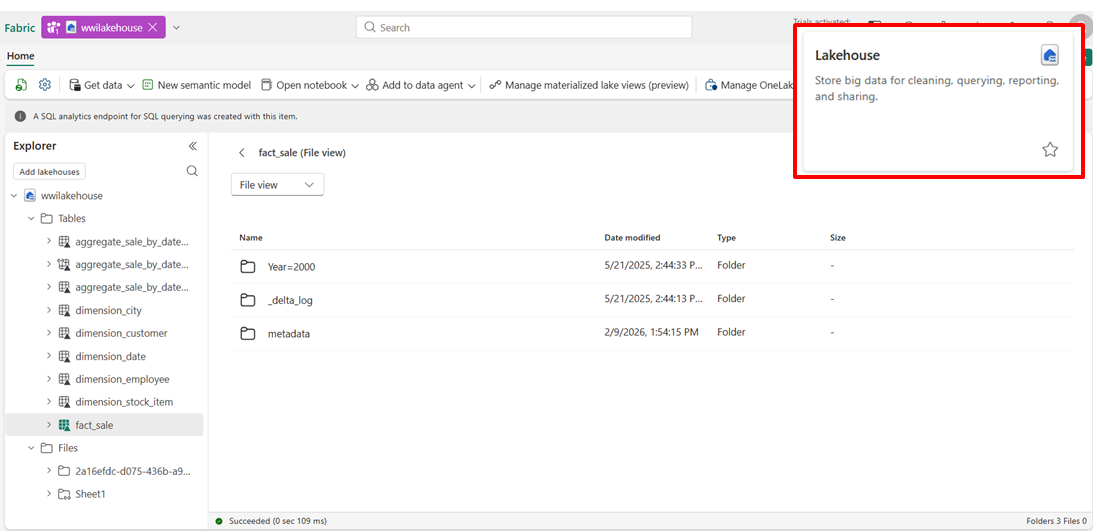
💡 Tips : Utilisez les Shortcuts pour ne pas copier vos données dans des buckets S3 ou ADLS Gen2. Si vous avez également des données déjà existantes dans vos workspaces, créez un shortcut dans le Lakehouse pour les analyser sans jamais dupliquer les données.
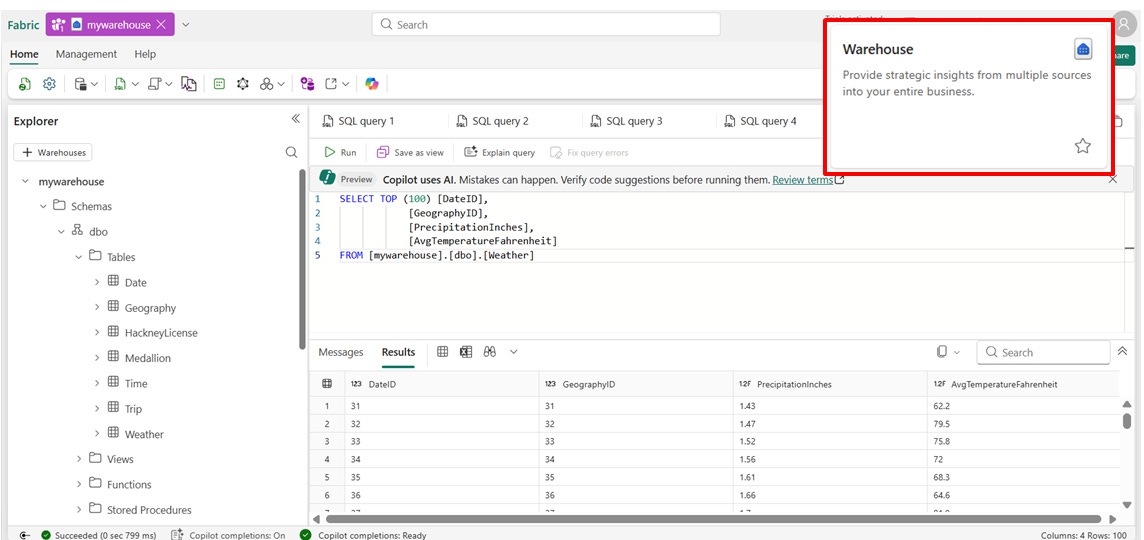
2. Le Data Warehouse : La puissance du SQL Structuré
C’est l’évolution SaaS du Synapse Dedicated Pool. Ici, pas de clusters à gérer, c’est du “Serverless” par défaut pour le SQL.
Ce qu’il faut retenir :
T-SQL Complet : Support total des commandes DDL/DML (
INSERT,UPDATE,DELETE) et transactions ACID.Adapté pour la gestion de données structurées uniquement.
Sécurité Granulaire : Définissez la sécurité à la ligne (RLS), à la colonne (CLS) et le masquage dynamique.
Idéal pour la création de rapports bi, modélisation dimensionnelle, équipes SQL-first, couche gold de l’architecture medaillon
3. L’Eventhouse : Le maître du Temps-Réel (RTI)
L’Eventhouse est conçu pour ingérer et analyser des flux de données massifs en temps réel. On parle de Big Data (Volume, Vélocité, Variété). Les eventhouses sont adaptés aux événements de streaming basés sur le temps avec des données structurées, semi-structurées et non structurées.
Ce qu’il faut retenir :
Basé sur le moteur Kusto (KQL Database)
Ingestion Streaming : Gère des millions d’événements/seconde (Logs, IoT, Clickstream).
Idéal pour des données de télémétrie et de journalisation, les données de série chronologique et IoT…
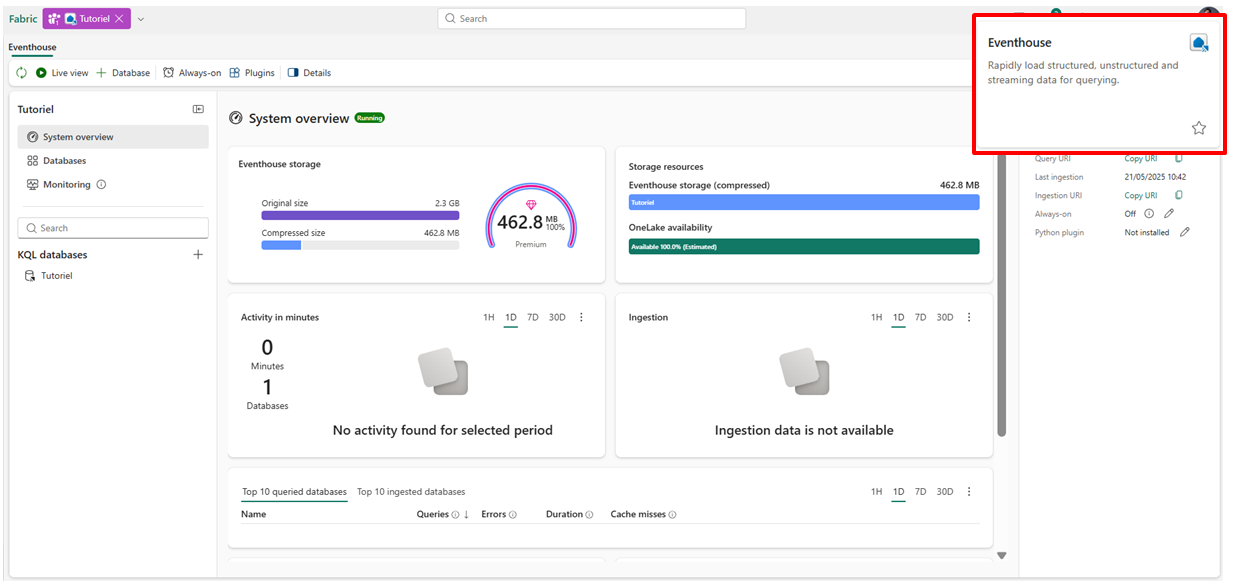
💡 Tips : Activez des règles sur “Fabric Activator” en complément sur vos streams pour déclencher des actions réelles (ex: envoyer un mail Teams si température > 50°C).
4. Cosmos DB : L'opérationnel NoSQL & IA
Cosmos DB est désormais une ressource native de Fabric. Créez une base NoSQL transactionnelle directement depuis votre workspace.
Ce qu’il faut retenir :
“Zéro-ETL” : Vos applications écrivent du JSON, et Fabric le convertit automatiquement en tables Delta Parquet dans OneLake.
Isolation : Vos requêtes analytiques ne consomment jamais les ressources (RU) de la base opérationnelle.
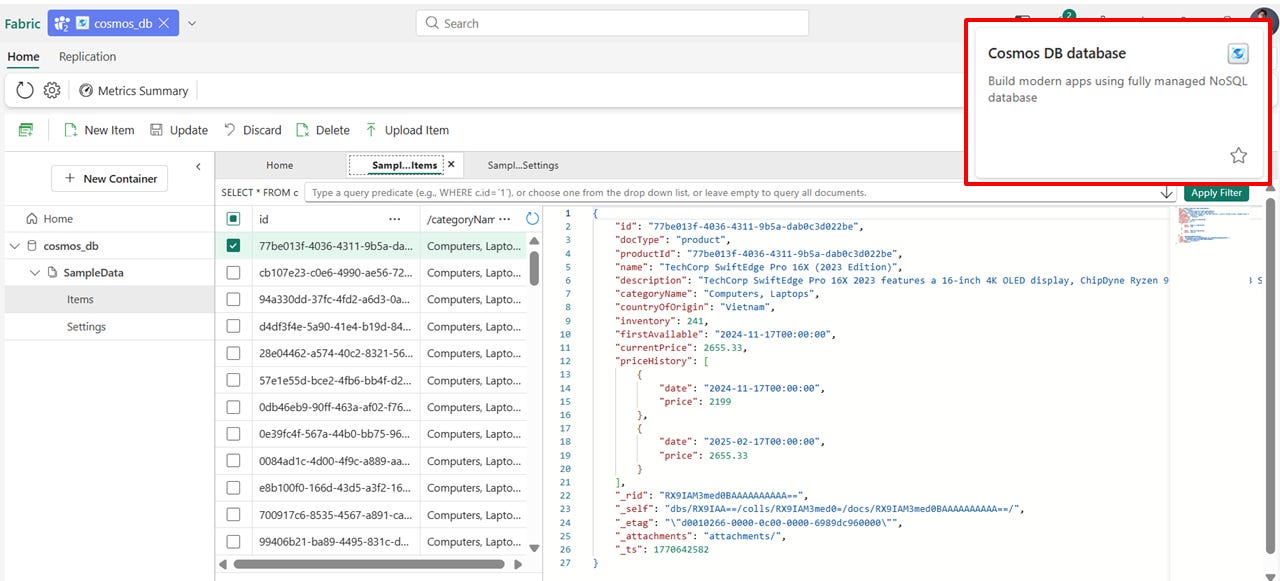
💡 Tips : Foncez pour vos projets d’IA (RAG). Cosmos DB gère nativement la Recherche Vectorielle pour servir votre Chatbot et l'analyser en même temps.
5. SQL Database : Le cœur opérationnel
Une base de données Azure SQL transactionnelle (OLTP) qui vit à l’intérieur de l’écosystème Fabric.
Ce qu’il faut retenir :
Vrai moteur OLTP : Conçue pour le backend de vos applications (Web, CRM).
Réplication OneLake : Chaque transaction validée est automatiquement répliquée et dispo pour l’analyse.
💡 Tips : Pour une nouvelle application, choisissez la SQL Database Fabric plutôt qu’une Azure SQL DB classique. Vous gagnez la partie “Analytics” gratuitement.
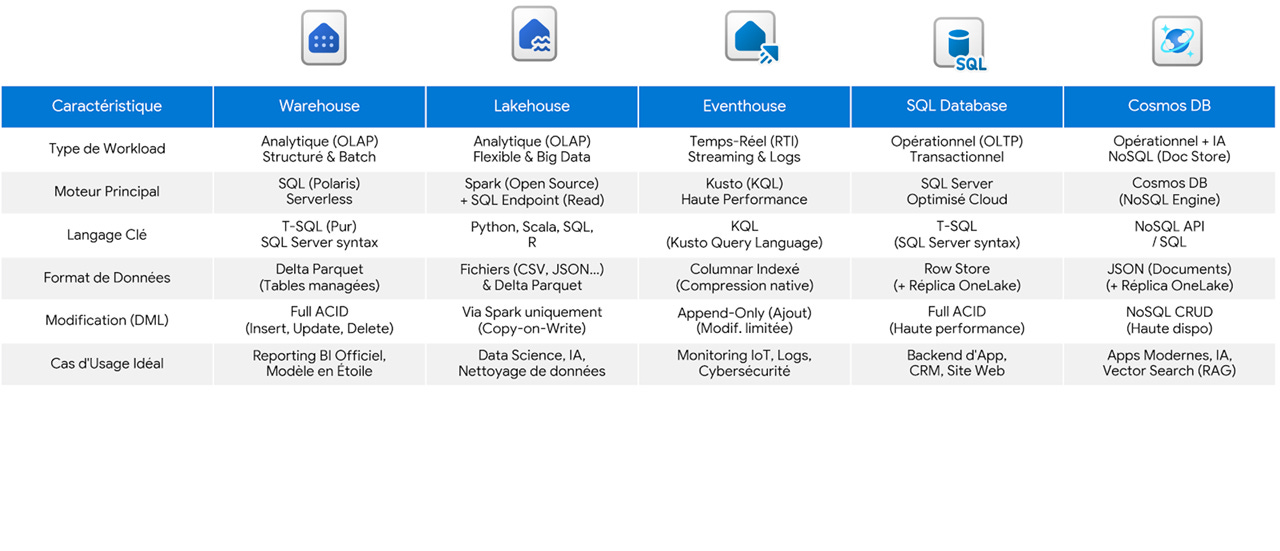
📊 Le Récapitulatif Visuel
Pour vous aider à mémoriser les différences, voici la vue d’ensemble comparative. Enregistrez cette image, c’est votre nouvelle anti-sèche !
🧭 Le Guide de Décision
Ne réfléchissez pas à la technologie. Réfléchissez à votre usage. Posez-vous ces questions dans l’ordre :
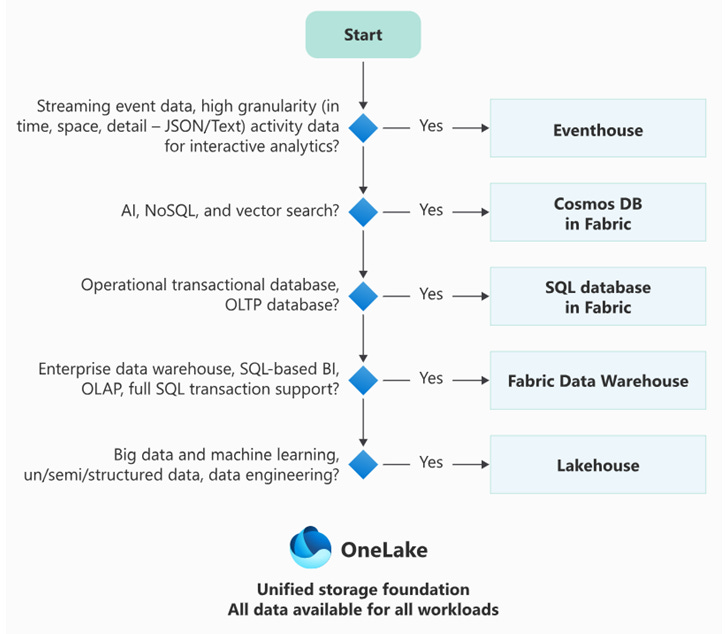
Question 1 : Êtes-vous en train de construire une nouvelle application ? C’est la distinction la plus importante : Opérationnel vs Analytique.
OUI : SQL Database (si relationnel) ou Cosmos DB (si JSON/NoSQL).
Pourquoi ? Transactions rapides millisecondes + Copie analytique auto.
NON (Je veux analyser des données existantes) : Passez à la question 2.
Question 2 : Vos données sont-elles déjà dans une application Azure ?
OUI (J’ai une Azure SQL ou une Cosmos DB en prod) : Mirrored Database.
Pourquoi ? Ne migrez rien ! Le “Mirroring” crée un jumeau numérique en temps réel.
NON (Fichiers, exports, sources variées) : Passez à la question 3.
Question 3 : Quelle est la vitesse et le volume de la donnée ?
STREAMING (Logs, Capteurs, Continu) : Eventhouse (KQL).
Pourquoi ? Le seul capable d’ingérer et d’interroger des millions de lignes/seconde.
BATCH (Chargements quotidiens, Fichiers) : Passez à la question 4.
Question 4 : Quelle est la compétence technique de votre équipe ? C’est souvent le critère décisif.
Team PYTHON / SPARK : Lakehouse.
Pourquoi ? Idéal pour le nettoyage de données “sales” et le Machine Learning.
Team SQL / T-SQL : Warehouse.
Pourquoi ? Productivité immédiate pour les équipes SQL Server. Sécurité fine native.
Conclusion
Oubliez les débats sans fin sur l'outil "ultime". La réalité du terrain, c'est que vos besoins changent plus vite que vos infrastructures. Dans l'écosystème Fabric, chaque brique a sa raison d'être :
Le Lakehouse pour la flexibilité et le moteur Spark.
Le Warehouse pour la rigueur du SQL d’entreprise.
L’Eventhouse pour dompter le temps réel.
Cosmos DB pour le NoSQL et l’IA générative.
SQL Database pour vos applications relationnelles.
Mais ne vous y trompez pas : la rupture technologique ne vient pas de ces outils pris séparément. Elle vient de OneLake. Que vous entriez par une application, un fichier plat ou un stream, vos données convergent vers un socle unique. Vous valorisez une source de vérité unique sans jamais payer la taxe de la duplication.
Mon conseil : Arrêtez de chercher l’outil parfait “sur le papier”. Choisissez celui qui colle à la culture de votre équipe (SQL vs Python) et à la nature de votre donnée. Si votre équipe est 100% SQL, ne les forcez pas dans un Lakehouse Spark sous prétexte que c’est “la mode”. Fabric est conçu pour faire le pont, pas pour créer des frictions.
Et vous, quel Data Store privilégiez-vous ? Répondez simplement à cet email ou ce post, je lis tous vos messages.
À la semaine prochaine pour continuer à explorer ensemble les entrailles de Fabric !
📚Ressources pour aller plus loin
Pour approfondir le sujet, je vous recommande ces lectures essentielles :