
OneLake : Pourquoi vous devriez arrêter de déplacer vos données dès aujourd'hui
Comprendre OneLake, le "OneDrive" de la Data

Bonjour à tous, je suis Antoine Wang.
J’aide les profils techniques à maîtriser l’architecture de Microsoft Fabric, et j’aide les décideurs à comprendre l’impact réel de cette technologie, sans le jargon inutile.
Mon objectif ? Vulgariser le complexe et vous donner les clés pour maîtriser Microsoft Fabric, une plateforme de données SaaS unifiée et alimentée par l’IA pour simplifier la gestion des données et l’analyse.
Cette newsletter est 100% gratuite. En vous abonnant maintenant, vous recevrez en exclusivité mon “One-Pager” pour cartographier l’ensemble de la solution Fabric en un coup d’œil.
Merci à celles et ceux qui me suivent depuis le début. Sans plus attendre, entrons dans le vif du sujet !
Avez-vous déjà compté combien de fois la même donnée est copiée dans votre entreprise ? Une fois dans mon PC en local, je le duplique en copie pour faire une autre version, une autre fois dans le Data Lake, puis dans mon Data Warehouse...
C’est ce qu’on appelle le “chaos des données”. C’est coûteux, risqué pour la sécurité, et franchement, c’est un cauchemar à maintenir parce que je ne me souviens plus de la source de vérité.
Microsoft Fabric introduit une solution radicale avec OneLake. Souvent décrit comme le “OneDrive de la donnée”, il promet de changer la donne.
Mais qu’est-ce que cela signifie vraiment pour votre quotidien ?
Qu’est-ce que le OneLake ?
OneLake représente le socle de stockage de Microsoft Fabric. C’est un lac de données unique et logique pour toute l’organisation.
Jusqu’à présent, chaque outil (SQL, Spark, BI) nécessitait souvent sa propre copie des données. OneLake élimine cette contrainte en fournissant un espace de stockage unique pour toute l’entreprise.
Ses 3 piliers techniques :
Solidité : Il est construit sur les fondations robustes d’ADLS Gen2.
Interopérabilité : Il unifie toutes les données au format Delta Parquet. Ce format open-source assure la fiabilité (ACID) et permet une lecture transparente par tous les moteurs de calcul (Fabric ou externes).
Gouvernance : La sécurité et la conformité sont appliquées centralement, quel que soit le moteur utilisé pour consommer la donnée.
Le bénéfice ? Une “seule version de la vérité”. Vos équipes techniques n’ont plus à gérer de multiples copies (ETL complexes), et vos équipes sécurité disposent d’un point de contrôle unique pour la gouvernance et la conformité. C’est l’efficience opérationnelle au service de la donnée.
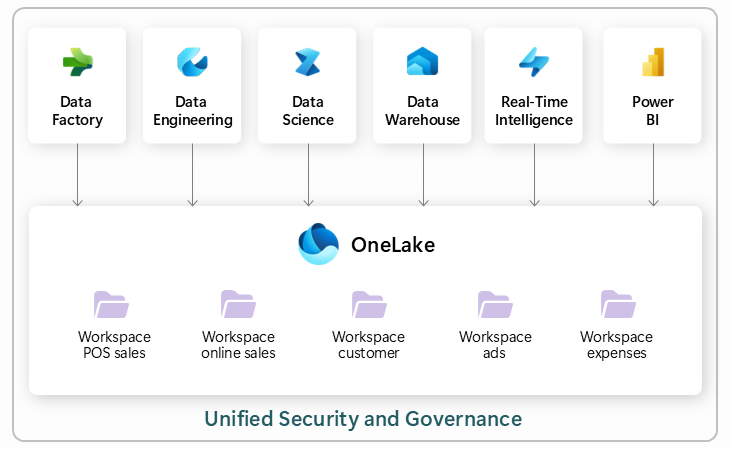
Virtualisation des Données : Le paradigme “Zero-Copy”
C’est ici que Fabric creuse l’écart. L’objectif est de stopper le déplacement inutile de la donnée. Fabric propose deux armes massives pour cela, selon la source de vos données :
1) Pour vos Fichiers : Les Shortcuts
Le Shortcut est un pont virtuel. Il permet à Fabric d’analyser la donnée là où elle se trouve, sans la copier.
En Interne : Le Marketing a besoin d’une table du Lakehouse “Ventes” ? Créez un Shortcut. Si les Ventes mettent à jour la donnée, le Marketing voit la modif à la seconde près.
En Externe (Multi-Cloud) : Vos données historiques sont sur Amazon S3 ou Google Cloud Storage ? Connectez-les via un Shortcut. Fabric analyse la donnée in-situ, sans frais de sortie (egress) et sans pipeline.
2) Pour vos Bases de Données : Le Mirroring
Les Shortcuts sont tops pour les fichiers, mais impossible de créer un “lien” vers l’intérieur d’une base de données verrouillée comme Azure SQL, Snowflake ou Cosmos DB. C’est là qu’intervient le Mirroring.
Au lieu de coder des scripts d’extraction, Fabric change les règles :
Réplication Continue : Vous connectez votre base et Fabric réplique les données en temps réel dans OneLake, basée sur les logs de transactions (similaire au Change Data Capture).
Transformation Automatique : La magie opère ici. Fabric convertit à la volée vos tables (format propriétaire) en Delta Parquet (format ouvert et optimisé).
Zéro Impact : Vous analysez la copie dans OneLake, sans ralentir votre base de production.
Le Résultat ? Que ce soit par lien (Shortcut) ou par réplication (Mirroring), vous avez tenu la promesse du “Zéro ETL”.
Modélisation : L’Architecture Médaillon (Best Practice)
Avoir un lac unique, c’est bien. Mais si on y jette tout en vrac, ça devient vite inutilisable. C’est là qu’intervient l’architecture recommandée par Microsoft : l’Architecture Médaillon.
L’idée est de raffiner la donnée en trois étapes logiques au sein de votre OneLake :
🥉 Bronze (Raw) : La zone d’atterrissage. On y dépose les données brutes, telles qu’elles arrivent des sources, sans modification. C’est l’historique complet.
🥈 Silver (Enriched) : La zone de nettoyage. On dédoublonne, on filtre, on typifie les colonnes. La donnée devient propre et fiable.
🥇 Gold (Curated) : La zone de consommation. La donnée est agrégée, modélisée en étoile (Kimball) et prête pour Power BI.
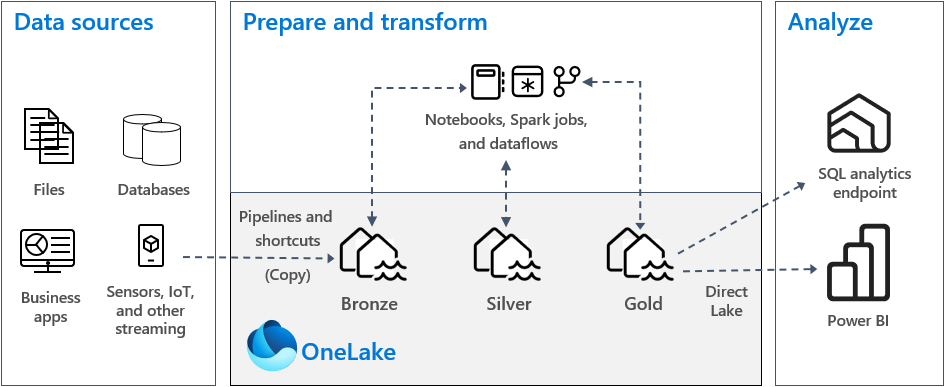
Pourquoi c’est vital ? Parce que OneLake permet de gérer ces trois états dans le même environnement. Vous passez des données brutes (Bronze) à la valeur business (Gold) sans jamais sortir de la plateforme.
Gouvernance et Sécurité : Approche “Domain-Driven”
Lorsque les équipes vont passer Microsoft Fabric en production, comment s’assurer que tout le monde ne voit pas tout ? Si tout est centralisé, est-ce l’anarchie ? Comment trouver rapidement les données de mon département métier ?
Pour cela, on applique une stratégie d’urbanisation appelée “Domain First”.
Imaginez un entonnoir de sécurité qui applique le principe de moindre privilège, du général vers le particulier :
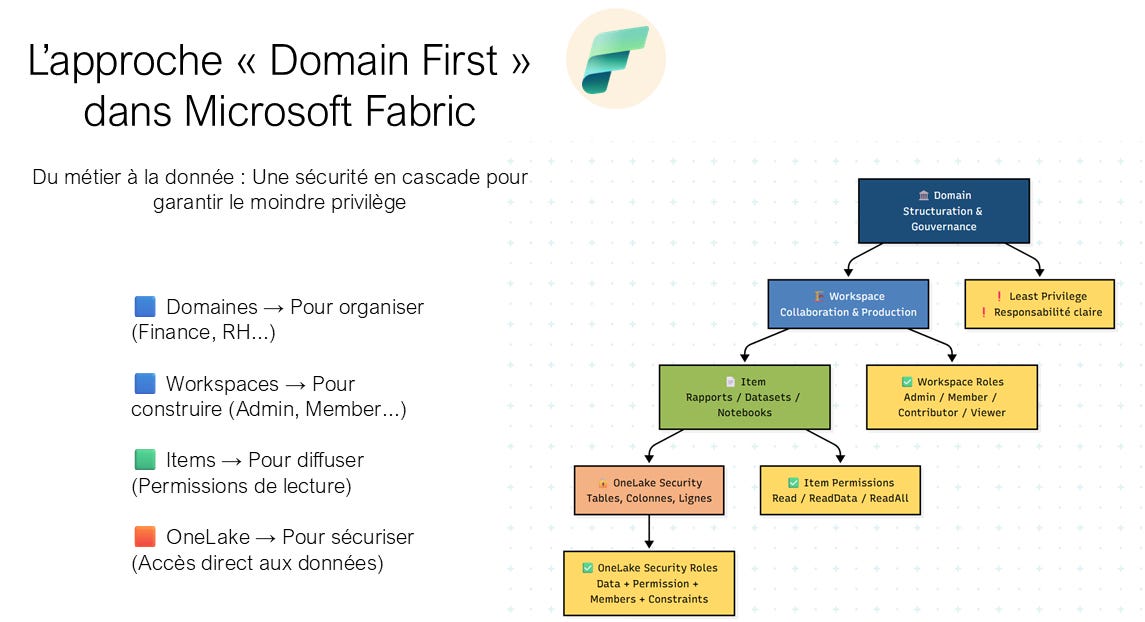
Niveau 1 : Domaines (Organisation Logique)
Les Domaines permettent de fédérer la gouvernance par unités métier (Finance, RH, Supply Chain). Ils offrent une décentralisation de l’administration et améliorent la découvrabilité via le filtrage dans le catalogue de données.
Objectif : Responsabiliser. Le “Domain Owner” pilote la gouvernance de sa zone, ce qui soulage l’équipe IT centrale et garantit que les accès sont validés par quelqu’un qui comprend le métier.
Niveau 2 : Le Workspace (La zone de collaboration)
Dans chaque domaine, on crée des workspaces. C’est ici que vous gérez qui construit et qui partage. La gestion des accès aux espaces de travail se fait via quatre rôles distincts :
Admin : Le niveau suprême. Il possède tous les droits du Membre, avec en plus le pouvoir de gérer le Workspace lui-même (le supprimer, le modifier) et d'ajouter d'autres Admins.
Membre : Il possède tous les droits du Contributeur, avec une capacité supplémentaire cruciale : il peut partager le contenu (Share) avec d'autres et publier des Applications.
Contributeur: Le rôle idéal pour les développeurs. Il peut créer, modifier et supprimer tout le contenu (Rapports, Lakehouses), mais ne peut ni partager, ni modifier les accès.
Lecteur: Le rôle en lecture seule. Il permet de consulter les rapports et les données, sans aucun risque de modification.
Niveau 3 : OneLake Security (Sécurité Granulaire)
Pour un contrôle fin, la sécurité est définie directement sur les objets de données, indépendamment du moteur de consommation :
Object-Level : Permissions spécifiques sur un Lakehouse ou un fichier (Read, ReadAll).
Row-Level Security (RLS) & Column-Level Security (CLS) : Application de filtres dynamiques basés sur l’identité de l’utilisateur directement au niveau du moteur SQL ou via des modèles sémantiques.
Découverte et Interaction
Microsoft Fabric gère l'accessibilité des données sur deux interfaces complémentaires :
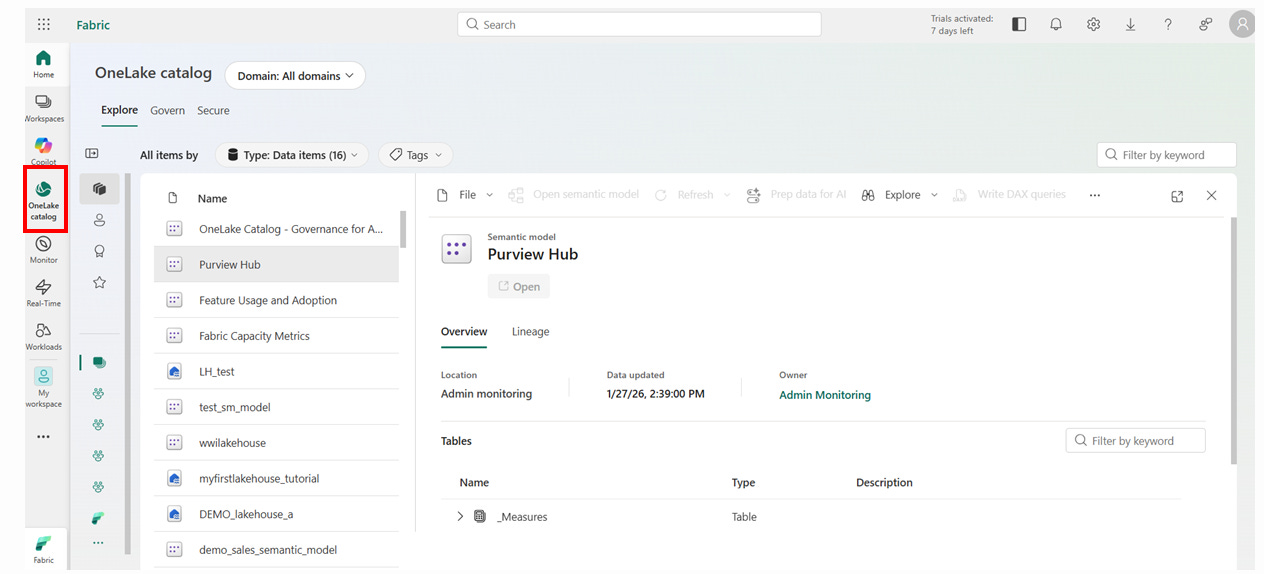
1) OneLake Catalog
Le OneLake Catalog est le moteur de gouvernance active de Fabric. Il transforme un lac de données opaque en un catalogue de services transparent.
Le Concept : C’est une vue unifiée de toutes les données (Lakehouses, Warehouses, KQL, Sémantiques) auxquelles l’utilisateur a accès, indépendamment du Workspace où elles résident.
La Gouvernance par l’Endorsement : Fini le doute sur la qualité de la donnée. Le Hub expose clairement les labels de confiance :
Master Data : La source de vérité absolue. Ce label désigne les données de référence (produits, clients) et ne s’applique qu’aux items contenant de la donnée (Lakehouses, modèles sémantiques).
Certifié : L’item a été validé par un réviseur autorisé. Il répond aux standards de qualité de l’organisation et est considéré comme faisant autorité pour un usage global.
Promu : Le créateur estime que l’item est prêt à être partagé et réutilisé. C’est le premier niveau de confiance pour encourager le self-service.
Réduction du TCO (Total Cost of Ownership) : En facilitant la découverte de données existantes (Lakehouses, Warehouses, Datasets), on évite aux équipes de recréer des pipelines pour des données qui existent déjà ailleurs. On favorise la réutilisation ainsi que sa valorisation plutôt que la recréation.
2) OneLake File Explorer
Pour combler le fossé entre vos outils locaux et le cloud, Microsoft propose le OneLake File Explorer. Une fois installé, votre Data Lake apparaît dans l’Explorateur Windows, intégrant OneLake au cœur de votre poste de travail.
Ce n’est pas juste du confort, c’est un gain de productivité technique :
“Edit-in-Place” pour les Dévs : Plus besoin de télécharger/modifier/uploader vos scripts ou fichiers de config. Faites un clic-droit sur un fichier dans OneLake, ouvrez-le avec VS Code ou Notepad++, modifiez, sauvegardez. La synchronisation vers le Cloud est automatique.
Ingestion Rapide (Quick Load) : Besoin de charger un fichier de mapping CSV ou des objectifs Excel pour une analyse ? Un simple Drag & Drop depuis votre bureau vers le dossier du Lakehouse suffit à rendre la donnée accessible aux moteurs Spark et SQL.
Point d’attention : Cet outil est conçu pour la productivité individuelle (fichiers de code, excels de référence, inspection). Ne l’utilisez pas pour migrer des données massives (ETL). L’explorateur Windows n’est pas fait pour transférer des Téraoctets. Pour les charges lourdes, utilisez toujours les Pipelines ou les Dataflows Gen2.
Conclusion
OneLake n’est pas “juste” un Data Lake de plus.
C’est un changement de paradigme : une seule copie de la donnée, accessible par tous les moteurs, gouvernée par le métier, et consommée sans friction. Là où les architectures traditionnelles empilaient silos, pipelines complexes et compromis, OneLake impose une idée simple mais radicale : amener le calcul à la donnée, et non l’inverse.
Le résultat ? Moins de copies, moins d’ETL, moins de coûts cachés — et surtout plus de clarté, de confiance et de vitesse pour le business.
Une question sur le OneLake ? Répondez simplement à cet email ou ce post, je lis tous vos messages.
À la semaine prochaine pour continuer à explorer ensemble les entrailles de Fabric !
📚 Ressources pour aller plus loin
Vous voulez creuser le sujet et mettre les mains dans le moteur ? Voici les liens essentiels :