
Sécuriser les connexions dans Microsoft Fabric

Bonjour à tous, je suis Antoine Wang.
J’aide les profils techniques à maîtriser l’architecture de Microsoft Fabric, et j’aide les décideurs à comprendre l’impact réel de cette technologie.
Mon objectif ? Vulgariser le complexe et vous donner les clés pour maîtriser Microsoft Fabric, une plateforme de données SaaS unifiée et alimentée par l’IA pour simplifier la gestion des données et l’analyse.
🆕 Nouveauté pour les lecteurs : j’ai créé Ask Fabric Mastery, un assistant IA qui répond à vos questions sur Microsoft Fabric & Power BI en s’appuyant uniquement sur les 23 éditions de cette newsletter. Réponses sourcées, sans hallucination, avec un lien direct vers l’édition d’origine.
👉 Testez-le maintenant : ask-fabric-mastery
🔑 Code d’accès : fabric-mastery-2026
Cette newsletter est 100% gratuite. En vous abonnant maintenant, vous recevrez en exclusivité mon “One-Pager” pour cartographier l’ensemble de la solution Fabric en un coup d’œil.
Merci à celles et ceux qui me suivent depuis le début. Sans plus attendre, entrons dans le vif du sujet !
La première étape de tout projet dans Microsoft Fabric, c'est de se connecter aux sources.
Quand on parle d’ingestion de données, on parle également de configuration de la connexion pour s’authentifier à la source.
Comment Microsoft Fabric peut accéder aux données ?
Les données sont sur du Cloud ou isolée dans un VNet ou On-Premises ?
Quelle méthode d'authentification et de gouvernance est imposée ?
Souvent, pour aller vite et lancer un PoV sur Microsoft Fabric, le réflexe naturel est d’utiliser son propre compte nominatif (login et mot de passe).
C’est rapide et efficace sur l’instant, mais pas propre !
Car le jour où vous passez en production et que ce développeur quitte l’entreprise, son compte Entra ID est désactivé, et 100% de vos pipelines s’effondrent. On passe alors plus de temps à faire de l’archéologie pour retrouver et réassigner les connexions qu’à réellement construire le flux.
Pourquoi c’est un problème pour vos équipes ? Parce que laisser les utilisateurs monopoliser les connexions avec leurs comptes personnels crée un “Single Point of Failure” (SPOF) critique. C’est transformer chaque départ ou changement de poste en crise technique inévitable.
Voyons voir quelles sont ces méthodes d’authenfication ainsi que les bonnes pratiques dans un contexte de mise en production.
Décryptage
Dans Fabric, la gestion des accès propose un panel d’options pour découpler l’identité du développeur de l’identité du pipeline. L’objectif est de créer une méthode d’authentification fiable et pérenne.
⚠️ Attention : Le menu d’authentification n’est pas magique. En fonction de la source de données ciblée (API, Azure SQL, Snowflake, etc.), Fabric ne vous proposera pas les mêmes options. Vous aurez généralement le choix entre :
Basic (Login / Mot de passe classique)
Organizational Account (OAuth 2.0, votre compte Entra ID)
Service Principal (SPN)
Workspace Identity
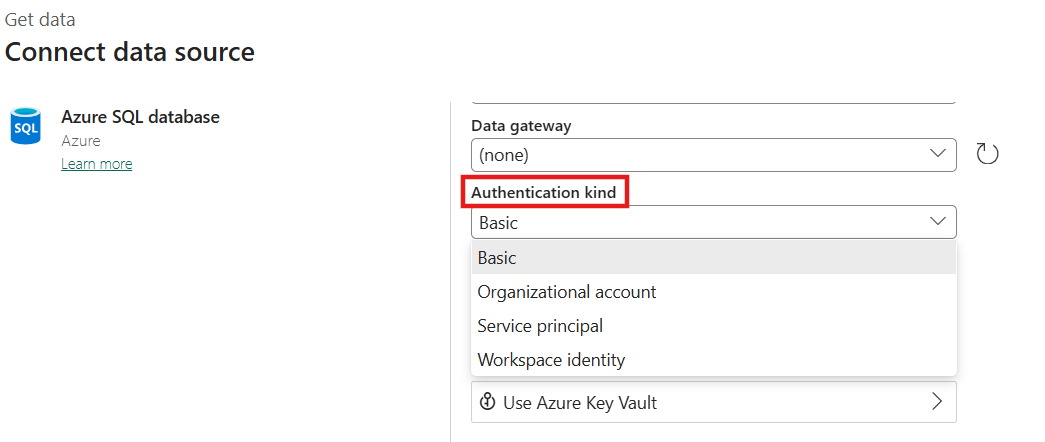
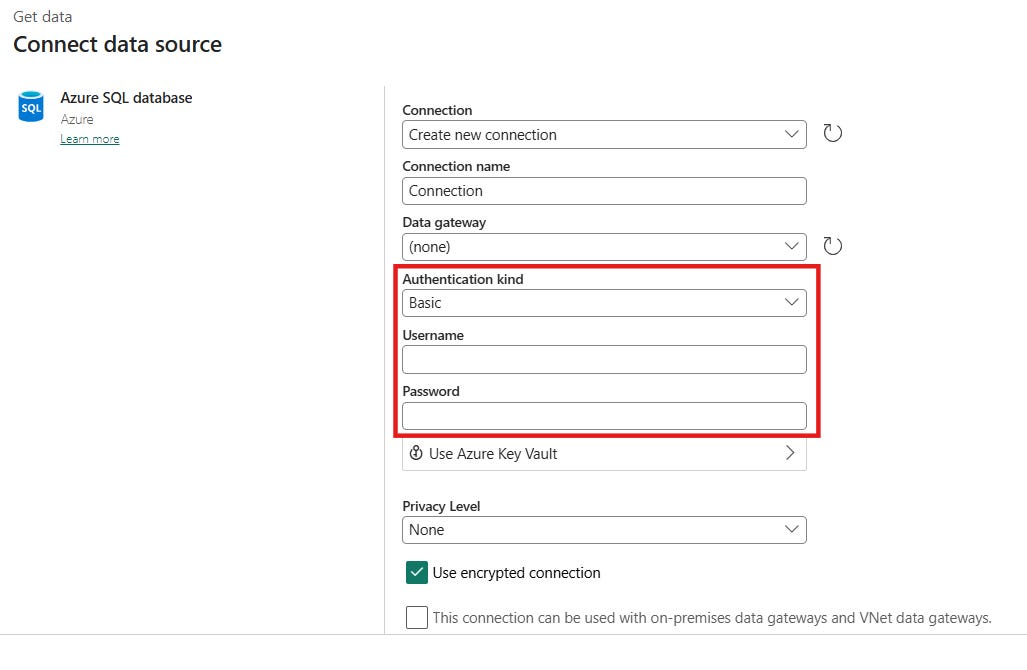
1. Basic
C’est quoi ? Le bon vieux couple “Login / Mot de passe”.
La réalité du terrain : C’est souvent la seule option pour des bases de données anciennes (On-Premises) ou des API très simples qui ne supportent pas l’OAuth.
Mon conseil : À utiliser uniquement si vous n’avez pas le choix (ex: un vieux SQL Server local derrière une Gateway). Si vous l’utilisez, le mot de passe doit être celui d’un compte de service générique (ex:
svc_fabric_read), jamais celui d’un humain.
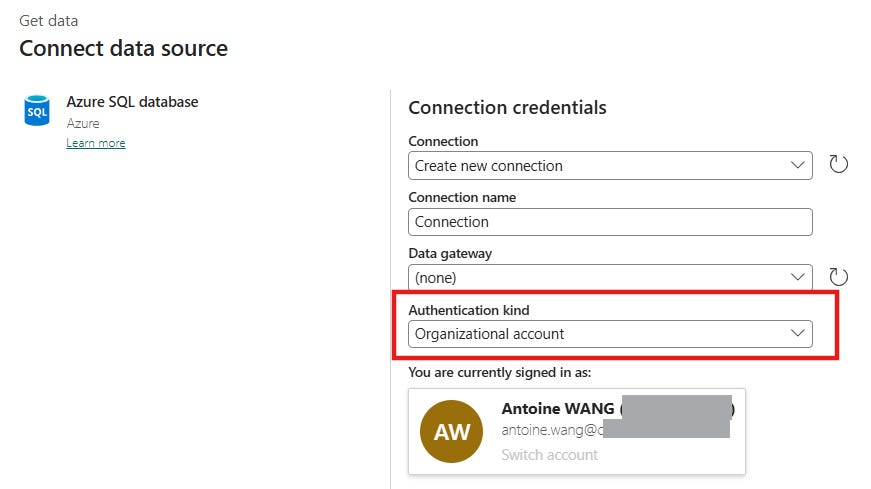
2. Organizational Account
C’est quoi ? C’est l’OAuth 2.0. Vous cliquez sur “Sign in”, une pop-up s’ouvre, vous validez avec votre compte Microsoft Entra ID (MFA, etc.).
La réalité du terrain : C’est l’option par défaut, ultra-rapide. Parfait pour le Dev et le PoV.
Mon conseil : C’est la zone de danger pour la Prod. Si un pipeline de production tourne avec cette méthode, vous avez créé une bombe à retardement liée à votre présence dans l’entreprise. À bannir des environnements de Prod.
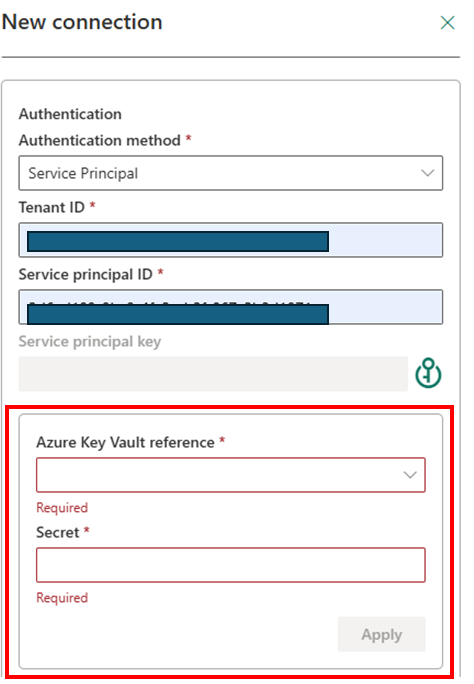
3. Service Principal
C’est quoi ? Une “App Registration” dans Azure. C’est une identité applicative pure, définie par un
Client IDet unSecret(ou certificat).La réalité du terrain : C’est le standard de l’industrie pour les connexions “Machine-to-Machine”. Elle est indispensable pour se connecter à des sources qui ne font pas partie de votre tenant Azure ou pour des API tierces.
Mon conseil : Pour que ce soit propre, ne tapez jamais le secret “en dur” dans Fabric. Stockez-le dans un Azure Key Vault et configurez Fabric pour aller le lire. Ainsi, l’équipe Sécurité peut faire tourner les clés sans casser vos pipelines.
4. Workspace Identity
Workspace Identity est un Principal de Service géré automatiquement, créé par les utilisateurs Fabric et associé à l’espace de travail.
La différence technique : Contrairement au SPN classique (App Registration) que vous devez créer et maintenir dans Azure, ici Fabric pilote tout. C’est un SPN invisible dont le cycle de vie est lié au Workspace.
La Tueur Feature : Elle permet une authentification transparente et sécurisée (sans secret à gérer) vers les services Azure, y compris les comptes de stockage protégés par pare-feu (Trusted Workspace Access).
Mise à jour majeure : Longtemps réservée aux items techniques, elle est désormais supportée par les Dataflow Gen2, Pipelines et Copy Job (à vérifier en fonction des connecteurs).
Mon conseil : C’est votre choix N°1 par défaut pour tout l’écosystème Azure/Fabric (ADLS Gen2, SQL DB). On supprime le workspace, l’identité disparaît. La gouvernance est totale et sans effort.
En pratique : Accès aux données Azure via Workspace Identity
Voici la méthode exacte pour ne plus jamais gérer de mots de passe :
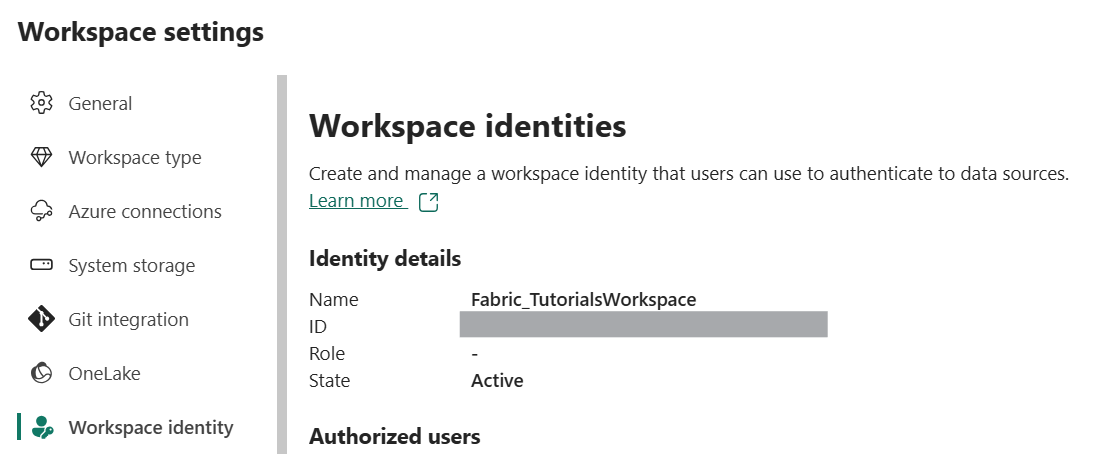
Étape 1 : Créer l’Identité (Côté Fabric)
Allez dans les paramètres de votre Workspace (sauf “My Workspace”).
Onglet Workspace identity.
Cliquez sur le bouton + Workspace identity.
C’est tout. Votre espace de travail a maintenant une existence propre dans l’AD.
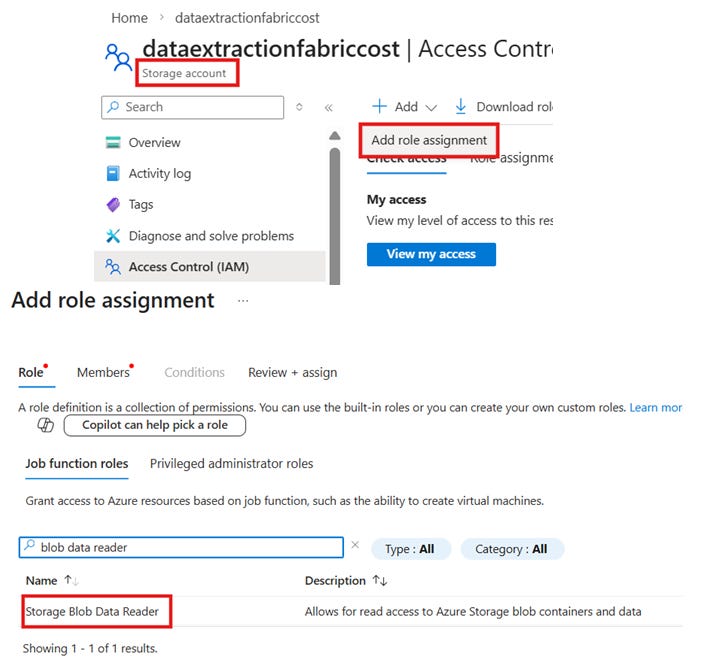
Étape 2 : Donner les droits (Côté Azure)
C’est l’étape que tout le monde oublie. L’identité existe, mais elle n’a le droit de rien faire.
Allez sur le portail Azure > Votre Storage Account.
Onglet Access control (IAM) > Add role assignment.
Choisissez le rôle précis (ex: Storage Blob Data Reader pour de la lecture seule).
Dans “Assign access to”, cherchez le nom de votre Workspace Fabric et validez.
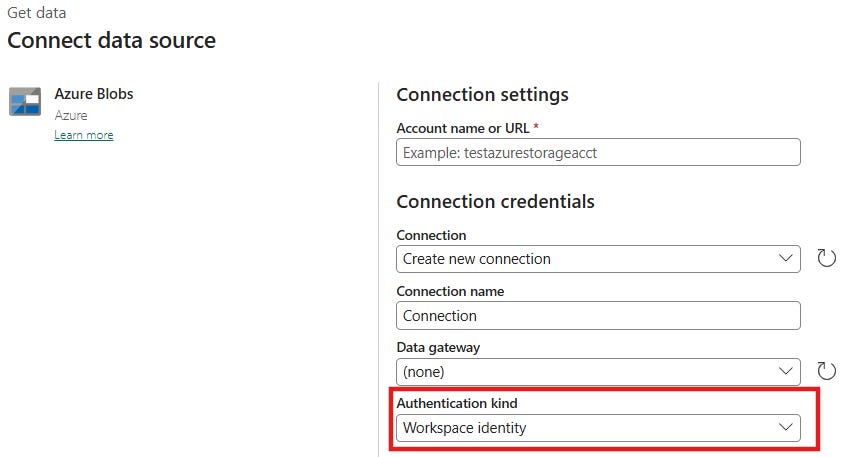
Étape 3 : Connecter le flux (Côté Dataflow Gen2)
Créez votre Dataflow Gen2.
Connectez-vous à votre Azure Blob Storage.
Dans “Authentication kind”, ne mettez pas “Organizational account”. Sélectionnez Workspace Identity.
Le tour est joué.
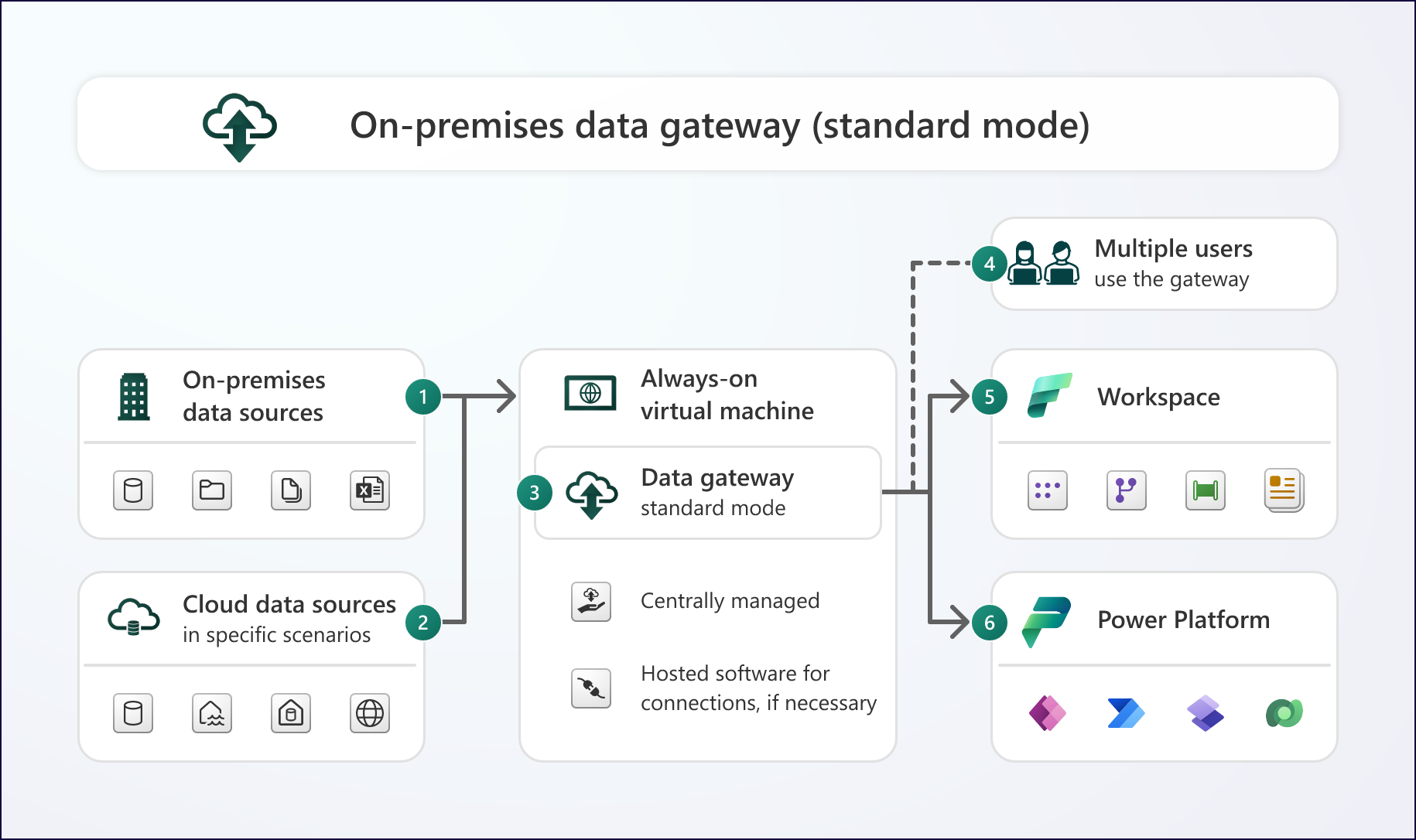
Quand l'identité ne suffit plus : Le cas obligatoire des Gateways (On-Prem & VNet)
Si vos données ne sont pas exposées publiquement sur internet, aucune identité cloud n’y accèdera directement. Il faut obligatoirement configurer une Data Gateway (Passerelle de données) en amont. Elle agit comme un pont : elle évalue les requêtes sur la machine hôte et transfère la donnée de manière sécurisée vers le cloud.
Il existe deux grands cas de figure où cette passerelle est indispensable :
Les sources On-Premises : Cela concerne les bases de données sur des serveurs physiques, les fichiers stockés dans un répertoire local d’entreprise, les machines virtuelles hébergées dans le cloud (IaaS), ou même lorsqu’une requête combine des données cloud et locales.
Les réseaux privés (VNet) : Dès qu’une source est isolée d’internet pour des raisons de sécurité (ex: Azure VNet). Cela inclut les data centers derrière un pare-feu, les VM cloud dans un VNet (IaaS), ou encore les services de base de données cloud (PaaS, comme Azure SQL) restreints à un réseau virtuel.
Matrice de décision
Pour sécuriser vos flux et forcer le bon choix technique, suivez cet arbitrage :
Q1 : Est-ce du prototypage rapide ou une analyse ad-hoc personnelle sur le cloud ?
👉 Organizational Account (OAuth). Le seul cas où le nominatif est accepté.
Q2 : La cible est-elle un service Azure/Fabric compatible Entra ID (ADLS Gen2, Azure SQL) ?
👉 Workspace Identity. La connexion meurt avec l’espace de travail.
Q3 : S’agit-il d’une API tierce, d’un SaaS ou d’une source cloud incompatible avec l’identité managée ?
👉 Service Principal (SPN). Implémenté via une Cloud Connection partagée.
Q4 : Les données sont-elles sur un réseau privé ou un serveur physique local ?
👉 Mettre en place une Data Gateway. Installée sur une VM dédiée (jamais un poste de travail), couplée à un compte de service local (Basic / Windows Auth), et partagée à votre groupe de sécurité de développeurs.
Conclusion
Si tu dois retenir une chose : Une architecture de données robuste survit au départ de son créateur ; si un pipeline de production dépend de l’adresse email d’un développeur ou d’une passerelle installée sur son ordinateur portable, ce n’est pas de la production, ça risque de casser à un moment donné.
Pérenniser vos connexions, c’est éliminer une dette technique invisible et garantir une continuité de service totale. C’est bâtir un socle gouverné (Cloud & On-Prem) pour que vos ingénieurs arrêtent de faire de la plomberie d’urgence et se concentrent enfin sur la valorisation de la donnée, sans trembler à chaque mouvement RH.
Et chez vous, c’est quoi la réalité du terrain ? Vos accès “On-Premises” sont-ils blindés par des Gateways en cluster, ou tournent-ils encore en équilibre instable sur la machine d’un dév ? On en discute en commentaire ! 👇
📚 Ressources pour aller plus loin
Pour approfondir le sujet, je vous recommande ces lectures essentielles :